
Here a video with highlights about Bayesian Deming regression, frequentist Deming regression (M- and MM- vesions) and Passing Bablok regressions applied to data with leveraged outliers.
As of tonight the package {rstanbdp} is available on CRAN.
Provides the Bayesian Deming regression sampled with a T error term. Per default the sampling happens at df = N-2 but can be tweakd down to d.f. = 1 for a very robust Cauchy distribution of the error term. Mild robustness is also possible with d.f. in a (usual) range of 6 – 10.
A linear heteroscedastic model is also provided. It can accomodate for the case where the variance grows linearly. It can be used to test for heteroscedasticity.
Hi,
I’m moving to piodag.github.io.
Here my first post
PBequi bias is confirmed with AUC arguments at n=1000 resolution
Since now a fork of the {mcr} package is avalable here (github). It is a stock 1.3.3 mcr version with added M-Deming and MM-Deming regressions. The plotBoxEllipses() function is also available and calculates the probability of the MD from the joint H0 hypothesis (slope=1, intercept=0) with a Chisq distribution (2 d.f).
It contains:
- The resulting .csv file.
- The .R script used for the Monte Carlo experiment with a couple of additional comments.
- The .R scripts needed for the processing of the raw data into a readable plot. I omitted one script (which is not mine, see the commented line), but is only needed to calculate CI tables for the power (inverted CI for nls regressions), thus not needed to plot the Subbotin curves.
You’ll see a lot of spaghetti code. Sorry for that, volks
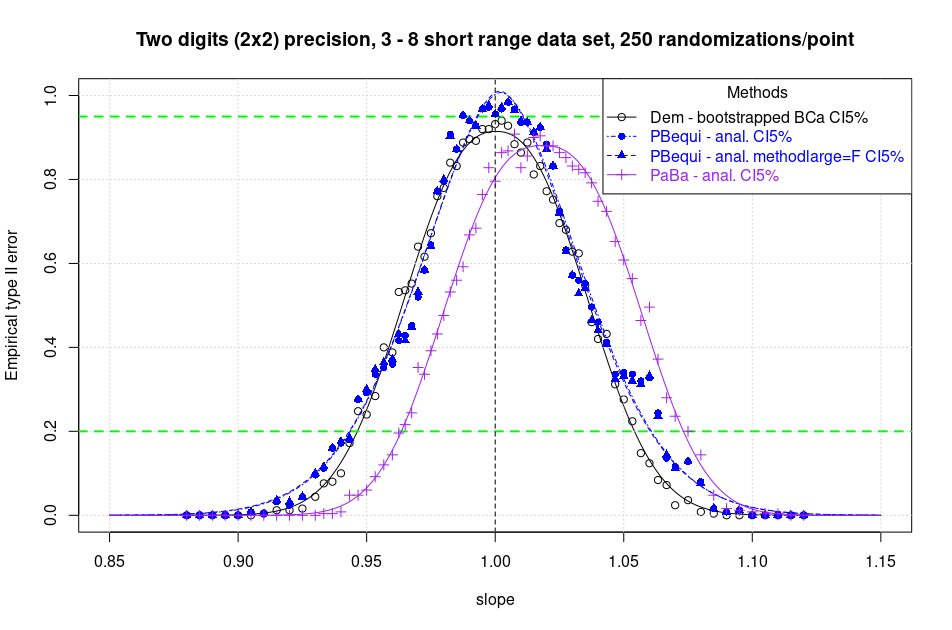
Recently I realized that in the new version of the R {mcr} package the “equivariant Passing Bablok” regression is available (Jakob Raymaekers, F. Dufey, arxiv, 2022) with the option “method.reg=PBequi” for the function mcreg() .
This version of PaBa is a big step forward in that it can be used even in the case where the null hypothesis does not strictly involve an intercept of zero and a slope of one. In fact, any use of the traditional 1983 PaBa method outside of this condition is generally not correct.
Attention has fallen on checking the issue of bias when the data have low precision and thus ties (or ties in the pairwise slopes) are present. Notoriously, the classical method suffers from a very strong bias (G. Pioda, 2021, pag. 31) and should never be used unless the precision of the data is at least 4 significant digits, as previously reported.
A first limited simulation with the same method published in 2021 (but with a resolution of 250 replications instead of 400) shows that indeed PBequi is definitely a big step forward in this as well. The coarse bias is dramatically reduced. But unfortunately it is not clearly eliminated. Note in this regard the asymmetry of the power curves at the 80 percent level (validation not rejected at 20 percent) in green in the graph provided here. Further investigation is needed to completely exclude the bias or to asses its magnitude.
Take home message. I suggest to all those who intend to use the PaBa method to abandon the classical 1983 algorithm in favor of the equivariant version offered by the R {mcr} package.
Remark: Unfortunately in these first runs at low data precision some unclear stability problems of the PBequi function in R prevented a simulation of the bootstrapped CI methods. It’s not clear if this issue is a local computational limit arising from the limited IT resources or something else.
Revisione dell’esame TAB 2
Link script con soluzioni in R
Attività di ripasso per la teoria statistica descrittiva sul dataset HoloTC
Script iniziale per statistica inferenziale
Più avanti seguiranno schede su:
- ANOVA/regressione
- Method Comparison
- Fallstudium
